Adventures in Optimization: OpenGL
Over the past few years, the hardware-accelerated rendering pipeline has rapidly increased in complexity, bringing with it increasingly intricate and potentially confusing performance characteristics. Improving performance used to mean simply reducing the CPU cycles of the inner loops in your renderer; now it has become a cycle of determining bottlenecks and systematically attacking them. This loop of identification and optimization is fundamental to tuning a heterogeneous multiprocessor system; the driving idea is that a pipeline, by definition, is only as fast as its slowest stage. Thus, while premature and unfocused optimization in a single-processor system can lead to only minimal performance gains, in a multiprocessor system such optimization very often leads to zero gains. - Cem Cebenoyan, NVIDIA, in GPU Gems
I spent the last several weeks experimenting, instrumenting my code, profiling performance, and optimizing. By way of summary, here is a sequence of timing and Shark profiles at various stages examining animated graphs of two implicit equations which represent different balances between numeric calculations and rendering complexity. Last night I wired up a Debug menu into GC4 to make comparisons easier.
Test Cases
ImplicitAnimation.gcf animates x2 + y2 + z2 + sin(nx) + sin(ny) + sin(nz) = 1.
ConcentricSpheresTest.gcf animates cos(n*sqrt(x2 + y2 + z2)=0.
Baseline: Software Rendering. Single Compute Thread (8.4s, 19s)


For a baseline, timing each animation using Graphing Calculator's software renderer using a single CPU core, gives 8.4s and 19s, respectively. The Shark profile looks like this, with most of the time spent calculating the equation, and more time rendering ConcentricSpheresTest.
OpenGL Hardware Rendering. Single Compute Thread (7.7s, 25s)


Switching to (single-threaded) OpenGL rendering, the timings become 7.7s and 25s. ConcentricSpheresTest actually slows down. The profiles show that two cores are now active in parallel as OpenGL renders the scene in the main thread while the WorkQueueConsumer prepares the next frame. Zooming into those pictures shows the main thread spending all of its time in OurSubmitTriangles/glDrawElements. In the second case, the overhead of submitting a huge number of tiny triangles to the GPU, (most of them occluded anyway), makes the animation slower despite the hardware accelerated rendering. However, this is already faster than GC 3.5, in which all computations were done in the main thread along with all rendering, cooperatively multi-tasked. Using even a single preemptive thread for calculations allows them to run independently in parallel with drawing and processing user UI events, as seen above.
Single-threaded OpenGL. Multiple Compute Threads (2.2s, 12s)
After breaking the numeric part of the work into jobs which can be run in parallel, the timings become 2.2s and 12s. The profiles now show a pronounced difference in character. The rendering time dominates the second case. The first case looks like the compute and rendering loads are similar. (Important note: the scale on each profile image is different. Comparisons are meaningful only within a single image. Shark, unfortunately, does not provide a time "Scale Bar" on these views. Is anyone on the Shark team reading?)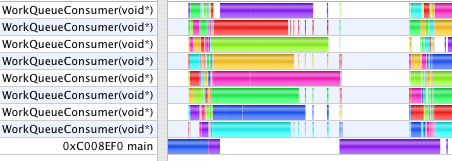
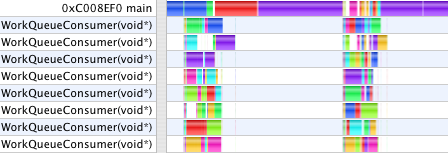
In both cases, still, drawing serializes the work. While one CPU core executing the main thread draws, all the other cores go idle waiting for the next thing to start.
Vertex Buffer Objects (2.1s, 12s)
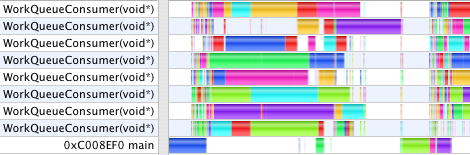
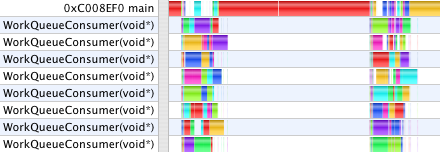
Using vertex buffer objects changes the animation timing to 2.1s and 12s. With VBOs enabled in Graphing Calculator, rendering is a two-step process where first, the arrays of vertex and normal vectors, triangles, and colors are submitted with a hint to cache them in VRAM. The command to draw then needs submit only a reference to these buffers. When spinning a static model, this is can be an enormous win, as all the data can stay in VRAM to which the GPU has fast access, and only a new rotation matrix need be sent each frame over the relatively slow connection between GPU and CPU. In these tests, however, we are animating a still model which changes the vertex data each frame.
Multi-threaded OpenGL (1.9s, 11s)
Enabling multi-threaded OpenGL is easy, but that is just the first step. Any glGet calls drain the MTGL pipeline and synchronize execution, eliminating the benefits of parallelism. Communication between parallel threads of execution is very difficult to get right. What it means for one thread to ask another thread about the (changing) OpenGL state when the relative order of operations between threads can vary is tricky, so the simplest approach to ensure correctness is to make all the communication one-way. After avoiding calls to glGetError, glGenBuffer, and other state queries, Shark still showed the GC main thread stalling at gleFinishCommandBuffer waiting for MTGL to drain in numerous circumstances. glDeleteBuffer was a spike in the profile. On mac-opengl, Richard Schreyer advised: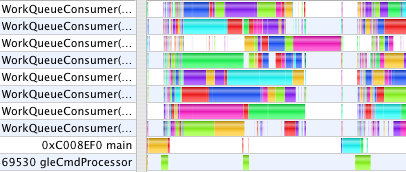
Unfortunately, the implementation of glDeleteBuffers (and all other glDelete*) still blocks in all cases right now. Your best workaround is to not delete the buffer object, but instead call glBufferData(size=0) to free the storage. You'll also need keep track of the used/free buffer object names yourself (I assume you're already doing this to avoid paying the same cost when calling glGen*). Textures can be handled in the same way (width=0, height=0, depth=0).
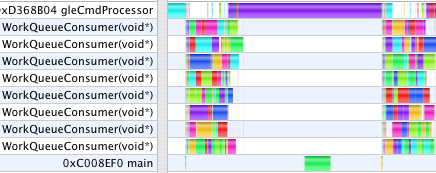
These profiles now show a new thread, gleCmdProcessor. Graphing Calculator makes all of its OpenGL calls from the main thread. With single-threaded OpenGL, all the CPU work done by the OpenGL driver also occurs in the application main thread. With multi-threaded OpenGL, GC's OpenGL calls made in main are queued into a command buffer which the gleCmdProcessor thread works through talking to the GPU. In the first case above, gleCmdProcessor has relatively little work to do. In the second case, it dominates the profile, and still blocks the WorkQueueConsumer threads from continuing on to the next step.
The problem is still that although GC can submit jobs to distribute the numeric work across all CPU cores, GC tries to render the last frame before submitting the jobs for the next frame. This serializes the work leaving cores idle while one is working alone on the rendering. Although MTGL can work in parallel, GC still must call glBufferData from the main thread to submit the model data, and that takes time.
Double Buffered Model Data (1.8s, 6.7s)
When GC finishes the numeric computation for one step, it saves those results away to prepare for starting the next step. Only after the slider has been advanced and the next calculations begun does the main thread then submit those saved results to OpenGL to render. The animation times are now 1.8s and 6.7s. Now, the work done in main and gleCmdProcessor overlap the numeric work done on jobs in the WorkQueue. The remaining areas in the first profile where the Work Queue threads are starved is due to the uneven complexity of the jobs the way GC chooses its data decomposition to parallelize the calculation. While creating more, smaller jobs would even out the work load, that also increases overhead and duplication of effort. In the second profile, the stall occurs because we only double-buffer the model data. The numeric computation gets one frame ahead, then waits while the main thread uses glMapBuffer to submit the last frame's model before it can save the newly computed model so that it can begin the next frame's calculation. We could use a circular buffer to get several frames ahead, but as we shall see in a moment, that ultimately won't help.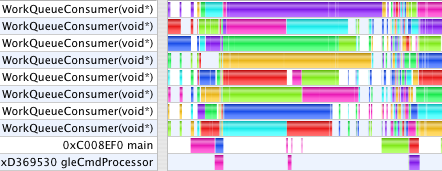
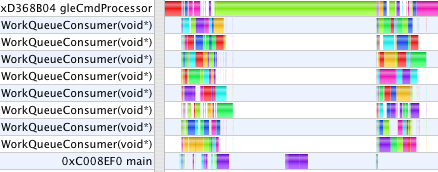
With this last step the GC user interface becomes unresponsive as MTGL can have commands for several seconds worth of frames buffered, and there is no way to kill them, or even to measure how many commands are buffered. This behavior occurs in the second case where the workload is dominated by rendering, but not in the first which is compute-bound evaluating functions. When moving a graph with the mouse, or even stopping an animation, one first sees up to several seconds of backlogged frames rendered before the 3D graph registers any feedback. To make GC responsive, glFlush is inserted into the draw loop each frame to intentionally block and drain the MTGL command buffer so it doesn't get more than a frame ahead. After this, the final timings for today are 1.8s and 8.9s.
Threads!
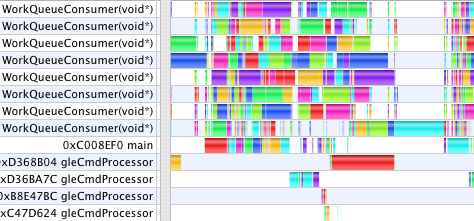
This profile shows GC running with three windows open, one of which has two OpenGL contexts (to illustrate a coordinate transformation with side by side views). Each context gets its very own gleCmdProcessor thread in multi-threaded OpenGL. However, as I have only one video card, they all must take turns talking to the same GPU to drain their command buffers. We also see here, that regardless of how many windows or equations GC is drawing, it creates (on this machine) 8 WorkQueueConsumer threads to process the jobs constructed by all windows. While one can create as many threads in software as one likes, the threads run on physical CPU cores. When there are more threads running that cores to run them, the scheduler must swap threads in and out to give them all time, increasing overhead. GC uses threads for two categories of work: to parallelize expensive operations across multiple CPU cores, and to improve user interface response time by avoiding any potentially lengthy tasks in the main thread which processes all user events. Multi-threaded OpenGL aids enormously in the latter respect, keeping the main UI thread responsive, even in cases where MTGL does not otherwise speed up the actual rendering time.
Next installment: Computed textures, color arrays and fragment programs