GetWRefCon
Graphing Calculator's calculations are for the most part emabarrassingly parallelizable. I spent several months last year expressing that parallelism in code to take advantage of muti-core systems. Yesterday I compared an Intel native build of GC4 on an 8-core system side by side with GC3.5 running under Rosetta. As expected, GC4 pegged the meter on all 8-cores:
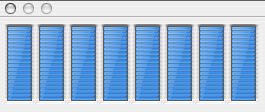
Imagine my surprise upon discovering that GC4 running native and parallel was no faster than GC3.5 running emulated on a single-core. Shark long ago earned a permanent spot in my dock as one of the best development visualization tools. It quickly informed me that 85% of the time was spent in GetWRefCon which calls GetWindowData which calls HIObject::IsRefValid and HLTBSearchRefTable which was serializing the parallel threads of execution. I had mistakenly thought of GetWRefCon as "free", misled by my 1980s-era Macintosh training when it was no more than a simple wrapper to dereference a WindowRecord structure field. Just another reminder that the only way to have any idea where your program is spending its time is to actually measure it. Stay tuned for a benchmarks report after I fix this.
Comments
You are calling GetWRefCon() from multiple threads?
I wouldn't be surprised if that failed completely. The Window Manager has never really been fully reentrant.
In the old days it would work because a WindowPtr was a pointer not a Handle and the refCon was just a field in the record pointed to, but in an opaque Carbon / Mac OS X world I'm not sure that's still the case.
It sounds like they put a mutex on the WindowPtr, which is good for safety but, as you found out, bad for speed.
How did you fix it?
Posted by: Eric Shapiro | May 28, 2007 11:30 AM
I was using the WindowRef only to get to a a DocumentRecord value, so I skipped the extra indirection and stored the DocumentRecord pointer directly. The details are boring and mostly related to header file separation. The code that does calculation doesn't include or know anything about documents, which is good, so pointers to anonymous structs come in handy here.
Posted by: Ron | May 28, 2007 11:39 AM